现金凯发·k8国际app平台Token 到底是什么?咫尺常见的用法-凯发k8首页(中国)官方网站登录入口

马俊杰是中国内地知名男艺东说念主,现为时间少年团队长、主场兼 C 位,2002 年 12 月 12 日诞生于河南郑州。
刚刚那段话是从某个 AI 大模子用具里复制粘贴下来的,是对于问题「马嘉祺是谁」的复兴。
没错,是马嘉祺,但 AI 会自动替换成「马俊杰」,有时期也会替换成「马杰伦」、「马祺祺」等。
可能有一又友说,这等于 AI 在胡编乱造。还真不是,除了名字除外,其他的信息都至极正确。
看成东说念主类咱们也会有雷同的事情,平时咱们会说,「你记不谨记阿谁谁,就阿谁谁,锻真金不怕火时长两年半,心爱唱、跳、Rap、篮球,哎叫啥来着」。
等于你能说出许多精确的细节,但等于想不起阿谁名字,这在心思学上叫「舌尖征象」。
咱们言语时大脑要走两个要领:第一步,语义索求——大脑锁定了这个「东西」的通盘属性,长相、功能、嗅觉。第二步,音韵索求——大脑去「档案柜」里找对应的阿谁名字发音。
舌尖征象的中枢在于:你还是完成了第一步(贯穿了它),但卡在了第二步(没找到阿谁词)。因为咱们东说念主类等于要先去贯穿寰宇,然后才能去抒发寰宇。
这个事情再不息计议下去,等于维特根斯坦那句「我语言的局限,意味着我寰宇的局限。」这就会变得很复杂,但我想知说念的是,那 AI 呢?「马嘉祺」这样的失误,是不是也跟它若何贯穿寰宇相关系?
AI 贯穿寰宇,跟东说念主差未几是正好相背的。我独特简化地来说,东说念主是得先有具体的东西,然后才有一张词汇表;AI 是先有一张词汇表,然后去找对应的描画和认识。
这样说比较抽象,我举个例子。
小时期,你看到一个红色的、带小点的东西。你摸到它坑洼的表皮,闻到那股特殊的幽香,咬下去感受到酸甜的汁水。你的大脑里形成了一个对于这个事物的完整综合体——表情、步地、气息、味觉、手感。大东说念主们告诉你,这个综合体叫「草莓」。

当你一会儿说不出「草莓」这两个字时,你脑子里依然有阿谁红色的影子、阿谁滋味、那种口感。
但 AI 不一样。
AI 的「大脑」——也等于模子——里先有一张弘大的清单,里面有个词汇叫「草莓」,或者 strawberry。AI 在检修中读了亿万次带有 strawberry 的句子,它发现 strawberry 平时和 red、sweet、fruit 出咫尺全部。通过这些统计概率,AI 在我方的数学模子里「免强」出了一个对于草莓的描画。它并莫得竟然见过、闻过、尝过草莓,它只是通过这个标签背后的数据关联,「模拟」出了它应该是什么神情。
以至,在 AI 的词汇内外,都莫得「草莓」或者「strawberry」这个词,它有的只是一串编号,我支吾说,这个编号可能是 23764。这个编号,就叫作念 Token,也等于大模子贯穿寰宇的初始。
用大模子,尤其最近装小龙虾 OpenClaw 的东说念主,对这个词信赖至极端庄。非论你在 AI 里作念什么,都需要浮滥 Token,许多大模子也都是按 Token 计费的。每次你跟 ChatGPT 对话、用 Claude Code 写代码、让 AI 帮你翻译一段话,你浮滥的等于 Token。你买的会员,试验上是在买 Token 的额度。
咫尺 Token 这个词还是大大高出了科技里的含义,有的东说念主说 Token 可以当职工福利,还有的东说念主说 Token 可以当工资——天然了,说这话的无一例外都是雇主。而更大的雇主,NVIDIA 的 CEO 黄仁勋在 2026 年 3 月 17 号 GTC 大会上说了一句话:Token 将会是一个万亿好意思元商场的基础。万亿。Trillion.
最近,Token 也有了汉文译名,叫词元。这个翻译我认为并不好,原因背面会说。不外为 Token 寻找汉文译名这个行径自身,阐明这个词的影响正在超出从业东说念主士而走向大家——一个汉文名字总比英文名字用起来浅显,而况更浅显出咫尺各样策略、国法以至法律当中。
为了浅显,在这里咱们依然照旧叫 Token。那问题是,Token 到底是什么?

咫尺常见的用法,Token 有三个含义。
一个是令牌的酷爱,等于你登录一个网站之后,服务器发给你的一串迅速字符,发挥「这个东说念主考据过了」。它自身莫得任何含义,但代表了你的身份。这个认识从 1970 年代就有了。
第二个是加密货币里的 Token,也等于代币。2017 年 ICO 激越的时期,这个词简直天天上新闻。多样加密货币、数字代币,试验上等于一串代码,莫得任何物理实体,但代表了某种价值。
第三个,等于咱们今天要聊的——AI 大模子里的 Token。若是用最粗拙的话来玄虚,Token 是语言的替代物。
要搞明晰 Token 是若何变成今天这个神情的,咱们得从新讲起。
1906 年,好意思国玄学家查尔斯·桑德斯·皮尔士(Charles Sanders Peirce)在一篇论文里建议了一个差异,叫 Type-Token distinction(类型-标志差异)。
皮尔士是干什么的呢?他是好意思国象征学的奠基东说念主,亦然一个逻辑学家。他其时在作念一件很有贪图的事情:发明一套用图形来作念逻辑推理的系统,他管它叫「存在图」(Existential Graphs)。
这个表面极其复杂,没主义在这里张开讲。粗拙来说,皮尔士试图把东说念主类的逻辑都用图示的模式抒发出来。就像将军干戈要看舆图一样——皮尔士我方就举过这个例子——你不会说「国土就在那里啊,要舆图干什么?」舆图让你看到地形里避讳的关系,逻辑图让你看到想维里避讳的关系。

在存在图里,基本上等于圈圈套圈圈的步地,但它遭逢一个问题。比如他在图上画了一个圆圈,代表「申辩」。然后他在另一个地方又画了一个圆圈,也代表「申辩」。咫尺问题来了——这是「两个圆圈」照旧「团结个圆圈出现了两次」?
若是你说是两个圆圈,那它们之间是什么关系?它们为什么酷爱一样?若是你说是团结个圆圈出现了两次,那阿谁「团结个」的圆圈在那儿?它不在纸上的任何一个具体位置。
这不是在抬杠。对于一个试图把逻辑推理严格步地化的东说念主来说,这是一个地基级别的问题。若是你连「这个图上有几个东西」都说不明晰,你若何去界说推理国法?
皮尔士用了一个很日常的例子来解释他的解决有计议。他说,你翻开一册书,一页纸上大约有二十个 「the」。若是你在数这本书有些许字,那这二十个 the 等于二十个词。但从另一个道理上说,英语里只消一个 「the」。那二十个只是它的二十次出现。
阿谁唯独的、抽象的 「the」——不存在于任何一页纸上、不成被任何声息说出来的阿谁 「the」——皮尔士叫它 Type(类型)。而纸上每一个具体的、印在阿谁位置的 the,他叫它 Token(标志)。
Type 是国法,Token 是实例。Type 是抽象的步地,Token 是阿谁步地每一次具体的、物理的炫夸。
用他我方的话说——Type 不存在,但它决定了存在的东西。

这个区剖析决了他的问题。从此他可以精确地说:逻辑图上的一个象征是一个 Token——一个特定位置上的具体实例;而这个象征所撤职的国法是一个 Type——一个不依赖于任何具体位置的一般法则。两个圆圈是两个 Token,但它们是团结个 Type 的两次出现。
那这个差异的后果若何样?
说真话,皮尔士的存在图在他谢世的时期简直莫得引起什么反响。他的论文写得太晦涩了,而况阿谁年代数学家和逻辑学家们更民俗用线性的代数象征来作念推理,认为绘制是绕远路。
但皮尔士意外间收拢了一个比逻辑图更根底的问题:任何象征系统——非论是语言、代码照旧逻辑——都同期存在于两个层面。一个是抽象的国法层面,一个是具体的实例层面。你必须同期跟踪这两个层面,不然你什么都说不明晰。
于是 Type-Token 这对认识被其他领域的东说念主拿走了。1930 年代,哈佛的语言学家都普夫(George Zipf)用 Token 来数每一个词每一次出现,用 Type 来分类每一个不重叠的词形,然后把词按频率从高到低胪列。
他发现了一个端正——排行第一的词出现的次数,梗概是排行第二的两倍,是排行第三的三倍,是排行第一百的一百倍。排行乘以频率,简直是一个常数。这等于都普夫定律(Zipf‘s Law)。它不单是英语的端正——汉文、法语、日语、拉丁语,简直通盘东说念主类语言都战胜团结个分散。
紧接着,1944 年,心思学家约翰逊建议了 Type-Token Ratio(类型-标志比)——用来推断一段文本的词汇丰富度。这个遐想到今天还在用。皮尔士阿谁「一页纸上有几个 the」的玄学问题,就这样变成了可以量化、可以画弧线、可以发现端正的科学用具。
然后,诡计机来了。

1960 年代,编译道理。这是 Token 在数字寰宇的第一次人命——它成了语法的替身。
当你写下一滑代码——比如「int x = 5;」——诡计机并不成径直读懂它。编译器作念的第一件事,等于把这行代码切碎。「int」是一个 Token,代表「整数类型」。「x」是一个 Token,代表变量名。「=」是一个 Token,代表赋值。「;」亦然一个 Token,代表语句兑现。
编译器不睬解代码的「酷爱」。它只需要把一语气的字符流切成一个个有身份的小单元,再按国法拼装。这个历程就叫 tokenization(词法分析)。
特地想的是,编译器里的 tokenization 和皮尔士的 Type-Token 完全对应。编译器先界说一套 Type——关键字、加减乘除这些运算象征、变量名这些类别——然后在代码中识别出每一个 Token,也等于这些 Type 的每一次具体出现。第一个「int」和第一百个「int」是团结个 Type 的不同 Token——和皮尔士数 「the」 的逻辑一模一样。
到这里,就和咱们咫尺使用的 Token 酷爱基本差未几了——都是把一种语言分割,然后浅显诡计机识别。但还有一个问题是之前莫得遭逢的:到底若何分割天然语言?
编译器切代码,其实是很幸福的一件事。因为代码是东说念主造的,它有严格的语法例则。「int」等于「int」,分号等于分号,空格等于分隔符。你不需要猜,国法——也等于阿谁 Type——还是事前详情好了,替你决定了从那儿切。
但天然语言不是东说念主造的。或者说,它是几十亿东说念主在几万年里「合造」的,莫得东说念主坐下来写过一份规格阐明书。

英语还好一丝。单词之间有空格,你至少知说念从那儿切。「I love cats」 三个词,三个 Token,清纯碎白。
但这个「按空格切」的有计议,一碰到现实就碎了。三堵墙同期堵在路上。
第一堵墙:词表爆炸。英语里 cat 是一个词,cats 是一个词,love、loved、loving 也都各是一个词。若是每个词形都算一个独处的 Token,英语光是有纪录的词形就有几十万个。德语更夸张,它可以把几个词黏在全部变成一个超长的复合词——你可能见过阿谁知名的例子,Rindfleischetikettierungsüberwachungsaufgabenübertragungsgesetz。这是一个对于牛肉标签监管干事转让的法律用语,六十三个字母黏在全部算一个词。你的词表要不要收录它?若是要收录,那雷同的复合词有些许个?词表需要无尽大。
第二堵墙:未登录词。你用检修数据建了一张词表,里面有十万个词。然后用户输入了一个不在词内外的词——一个品牌名、一个网罗流行语、一个拼写失误。若何办?早期的作念法是把通盘不领路的词救济标志成一个特殊象征「UNK」,酷爱是「未知」。这就形成了一个悖论:比如「蔡徐坤」不在词内外,你去问 AI「我想了解蔡徐坤」,AI 看到的是「我想了解 UNK」。你整句话里最关键的阿谁信息,对 AI 来说是一派空缺。
第三堵墙:许多语言莫得空格。汉文莫得空格,日语莫得空格,泰语莫得空格。全寰宇大多数东说念主说的语言,词和词之间是不分开写的。比如「乒乓拍子卖了些许钱」,从那儿切?乒乓球、拍、卖,照旧乒乓球、拍卖?「了」算一个词照旧一个语法标志?这不是一个有程序谜底的问题。汉文分词到今天都是天然语言处理里的经典艰巨。
是以你看,「按空格切」这个最直观的有计议,只在很有限的条款下管用。
民众想了别的主义。往上走,词干索求,把 cats 收复成 cat,把 loving 收复成 love,这样词表就小了。但你得为每种语言手写国法,英语的不适用于德语,德语的不适用于汉文,对非欧洲语言基本没用。往下走,按字母切。「hello」 切成 h、e、l、l、o,词表只消 26 个字母加一些象征,都备不会爆炸,也都备不会碰到未登录词。但代价弘大——序列太长了。一个句子按词切只消 50 个 Token,按字母切可能有 300 个。序列越长,检修越慢,后果越差。
上也欠亨,下也欠亨,中间也莫得通用的有计议。
直到 2016 年。

2015 年到 2016 年,神经机器翻译——等于用深度学习作念翻译——正在快速崛起。Google、百度都在押注这个处所。后果比传统的统计翻译好了一大截,但有一个问题永恒解决不了:生词。
神经翻译模子需要一张固定的词表,平时是三万到五万个词。但翻译天生等于一个灵通词汇的问题——你永远不知说念用户会输入什么。一个德国城市的名字、一个新缔造公司的名字、一个刚发明的科学术语,只消它不在词内外,模子就只可输出 「UNK」——「我不领路」。
之前的解决主义是「查辞书兜底」——碰到不领路的词,就去辞书里找对应的翻译硬塞进去。但这个作念法很拙劣。最初你得有辞书,其次辞书里也不一定有这个词,终末硬塞进去的翻译平时和前后文格不相入。
爱丁堡大学的 Rico Sennrich 和他的共事——Barry Haddow 和 Alexandra Birch——领路到一件事:其实许多「生词」并不是竟然全新的。东说念主名可以通过音译处理,复合词可以完了翻译,同源词可以通过形态变换识别。也等于说,许多词的翻译可以在比「词」更小的单元上完成。
问题是:这个「更小的单元」是什么?若何切?
Sennrich 的想路很粗拙:别让东说念主来决定若何切了,让数据我方决定。他用了一个叫 BPE 的算法——Byte Pair Encoding(字节对编码)。
这个算法也不是 Sennrich 的原创,事实上在 1994 年就有东说念主建议来了,作家叫 Philip Gage,著作发表在 《The C Users Journal》杂志上。这不是一个学术期刊,而是一册面向 C 语言步伐员的实用时候杂志,主要刊登编程手段和小用具。放在今天大约相称于在 Medium 或者某个时候博客上发了篇帖子。
这也不是一个很好的压缩有计议。Gage 在论文里我方就承认,BPE 的压缩率不如其时还是无为使用的 LZW 算法——等于 zip 文献使用的那种算法。
他说 BPE 的上风是解压步伐独特小、解压速率独特快,顺应一些内存有限的场景。多有限呢?比如早期的工业抛弃器、某些专用仪器、资源极其受限的微处理器。这些开荒可能只消几 KB 的内存,一个程序的 LZW 解压库放不进去,但 BPE 的解压代码几十行 C 就能惩办。
但更无为的场景——也等于个东说念主电脑里——固然内存远远不成跟咫尺比较,但也还是是 MB 级别的了,反而硬盘空间和网罗带宽垂危,需要更高的压缩率。
它的唯独上风(解压步伐小)只在少量数东说念主体恤的场景里有道理,而它的颓势(压缩率不如主流有计议)在大多数东说念主体恤的场景里很明白。
这就好比说,你有一台雪柜,制冷不行,耗电也不行,唯独的上风是这是个大象步地的,浅显把大象装进去。
咫尺大象来了。
通盘东说念主类的语言库,等于那头弘大无比的大象。Sennrich 看出了一个关键的类比:数据压缩在作念的事情——找到重叠出现的模式,用更短的象征代替它——和语言切分需要作念的事情,在结构上是一样的。一个在极小众场景里发明的压缩算法,就这样被搬到了天然语言处理。

把这头大象装进去,系数分三步:
第一步:把通盘翰墨打散成最小的单元——字节。英翰墨母一个字节,汉文汉字在 UTF-8 编码(一种通用的字符编码程序)下平时是三个字节。这一步不需要任何语言学学问,非论你是什么语言,到了字节这一层,民众都一样。
第二步:扫描通盘检修语料,统计哪两个相邻的字节出咫尺全部的次数最多。比如在英文里,t 和 h 平时挨着出现,因为 the、that、this、think 这些高频词都以 th 开头。好,把 t 和 h 合并成一个新的象征 th,分拨一个新的编号。因为 0 到 255 还是被基础字节占了,是以第一个新象征从 256 初始。
第三步:在合并之后的基础上,再统计。th 和 e 平时全部出现——合并成 the,编号 257。th 和 a 也平时全部——合并成 tha,编号 258。
如斯反复,迭代几万次。每一次迭代,都把现时出现频率最高的一双合并成一个新的象征。
道理等于如斯。莫得语法分析,莫得辞书,莫得任何东说念主类对语言的贯穿。等于数数。
最终你会得到一张词表——平时是几万到十几万个 Token。这张词内外有什么?常见的英文单词,比如 the、and、is,各自是一个完整的 Token。常见的汉文汉字,比如「的」、「是」、「我」,也各自是一个完整的 Token。
但不常见的字、不常见的词、不常见的组合——它们莫得攒够鼓胀的频率被合并成独处的 Token,就只可留在碎屑情状。比如 「Krzyzewski」——前杜克大学篮球主素质老 K 的姓——会被拆成五六个碎屑。
但关键是:它不会湮灭。非论多淡薄的词,BPE 都能把它拆成已有的小碎屑来闪现。永远不会输出「UNK」。
还谨记前边的三堵墙吗?词表爆炸、未登录词、莫得空格——BPE 一次性全部推倒。词表大小可控,几万个就够;任何新词都能用现存碎屑拼出来;不需要空格,因为切分完全由统计驱动。
若是你还谨记前边说的都普夫定律——少数词出现频率极高,巨额词出现频率极低——你就会发现 BPE 在作念的事情,试验上等于把都普夫定律翻译成了一张编码表:高频组合变成短编码,低频组合留在长编码。和信息论的精神来因去果:常见的东西应该占更少的空间。

讲到这里,值得想考一个问题:BPE 和之前拆 Token 的模式,最试验的不同是什么?
从皮尔士到都普夫到编译器,咱们都最初需要去贯穿国法,也等于贯穿 Type,才能去作念分析和拆分。皮尔士说 「the」 是一个词,那是东说念主类的语言范例。编译器说 `int` 是关键字,那是步伐语言遐想者写下的国法。
一百一十年来,Token 可以是任何东西的替身,但 Type——阿谁界说「什么是一个有道理的单元」的职权——永恒在东说念主类手里。
但 BPE 不一样。
BPE 根底不问「什么是一个词」。它不体恤语法,不体恤词根,不体恤任何东说念主类对语言的贯穿。它只作念一件事:数字节对出现了些许次。the 成为一个 Token,不是因为有东说念主告诉系统 「the 是英语里的定冠词」,而只是是因为 t-h-e 这三个字节碰劲在检修数据里反复挨在全部。
换句话说——BPE 的词内外莫得 Type。或者更准确地说,BPE 用 Token 的统计分散取代了 Type。它不需要东说念主类来界说什么是一个有道理的语言单元,它让频率我方「涌现」出有道理的单元。
这亦然为什么 BPE 是一件极其刚劲的刀兵——它不依赖任何语言学学问就能处理通盘语言,因为它根底不需要知说念什么是「词」。Sennrich 在论文里解决的阿谁问题——生词——也因此被透顶消解了:当你的系统不再以「词」为单元,就不存在「词内外莫得的词」这回事。任何文本都可以被拆到字节层面,然后从字节往上合并到它在词内外能达到的最高层级。

但这还不是荒谬。
2018 年,OpenAI 发布 GPT-2 的时期,对 Sennrich 的 BPE 作念了一个遑急的改良。
Sennrich 原版的 BPE,来源是字符——英翰墨母、汉文汉字、标点象征这些。这意味着你得先告诉系统「这些是英翰墨符、这些是中翰墨符、这些是阿拉伯翰墨符」——固然比「告诉系统什么是一个词」要粗拙得多,但你仍然需要一套字符表,而况不同语言的字符表不一样。
OpenAI 的作念法是再往下走一层:不从字符开拔,从字节开拔。

什么是字节?诡计机里通盘的东西——翰墨、图片、音乐、视频——在最底层都是 0 和 1。每 8 个 0 和 1 构成一个字节。一个字节能闪现 256 种不同的情状,从 0 到 255。
在 UTF-8 编码下,一个英翰墨母恰好是一个字节。字母 A 是字节 65,B 是 66,z 是 122。一个汉文汉字需要三个字节。比如「马」这个字,在 UTF-8 里是三个字节:229、184、172。不是一个数字,是三个数字拼在全部。
改良版被称作 Byte-level BPE,简称 BBPE,来源等于这 256 个基础字节。非论你输入的是英文、汉文、阿拉伯文、缅甸文照旧 emoji,到了字节这一层,民众都是 0 到 255 之间的数字,莫得区别。然后 BPE 在这个基础上作念合并——高频的字节对合并成新象征,再合并,再合并,迭代几万次,生成最终的词表。
BPE 的处理对象照旧天然词汇,但 BBPE 不再需要知说念寰宇上有些许种翰墨。它不需要一张字符表,不需要知说念汉文和英文的区别,不需要任何干于语言的先验学问。万物皆字节,字节皆可合并。
这等于为什么 GPT 系列模子能「处理任何语言」——不是因为它学过通盘语言,而是因为它的来源鼓胀低。低到了字节。在字节眼前,通盘语言一律对等。
听起来很好意思好,好意思好到不现实,对吧?

不对等在检修之前还是发生了。
英翰墨母一个字节等于一个字符,BPE 从一初始就在处理有道理的单元。而汉文汉字需要三个字节,BPE 得先把这三个碎屑合并回一个字,才能初始处理「有道理」的东西——它的起跑线就比英文靠后了一步。
再加上检修数据里英文内容占都备多数,英文的字节组合有巨额的统计维持去合并成完整的单词以至短语,而汉文的字节组合能合并回单字就可以了,更别说词组。
举个例子。在 GPT-5 的 Tokenizer 里,「字节逾越的短视频平台抖音」,系数 12 个汉字,需要用 11 个 Token;而英文版 「ByteDance‘s short video platform Douyin」 有 40 个字母,只需要 9 个 Token——要注释,ByteDance 和 Douyin 以至都不是实在的英文单词,但在英文里依然效用更高。
咱们可以仔细看一下「字节逾越的短视频平台抖音」是若何变成 Token 的。「视频」和「平台」都是一个 Token,「抖」占了两个 Token。
这里多解释一下,为什么一个汉字会占据两个 Token。像前边所说,BBPE 不是面向字符编码,而是面向字节编码。「抖」对应的编码是 230、138、150,很可能在数据库里,230 与 138 的组合是高频的,但再加上 150 的话频率就没那么高了,是以编码 230、138 对应了一个 Token,而编码 150 单独对应一个 Token。
每个字单独编码,偶尔两个字能合并,但也有些字需要拆分。总体上,汉文的 Token 浮滥等于比英文高。
那这意味着什么呢?
大模子是按 Token 计费的。OpenAI 的 API,每一千个 Token 收些许钱,证据实在写在价钱表上。你浮滥更多的 Token,你就付更多的钱。

而况不单是付钱的问题。大模子有崎岖文窗口(context window,模子一次能「记取」的内容量)——等于它一次能处理的 Token 总量上限。GPT-4 的崎岖文窗口是 128k 个 Token。
这意味着若是你用英文,你可以在一次对话里塞进去梗概十万个英文单词——差未几一册中等篇幅的演义。但若是你用汉文,雷同的 128k 个 Token,你能塞进去的内容就要少许多。
雷同的窗口,汉文用户能说的话更少。
付更多的钱,得到更少的空间,得回更短的复兴。这等于 Token 不对等的经济学。
但汉文至少还算「大语言」。检修数据里汉文内容固然不如英文多,但也有相称的领域,足以让常用汉字被合并成独处的 Token。
实在惨的是那些小语种。
频年来,多项商酌对这个问题作念了系统的测算。他们发现,雷同的语义内容,用不同语言抒发所浮滥的 Token 数目相反可以达到十几倍。
英文是基准——浮滥最少的 Token,汉文梗概是英文的 1.5 到 2 倍,日语、韩语雷同,缅甸语、藏语、阿姆哈拉语等语言,雷同的内容可能需要英文 5 到 10 倍的 Token
为什么?因为这些语言在检修数据里简直不存在。BPE 在检修的时期莫得见过鼓胀多的缅甸文,是以缅甸文的字节组合从来莫得契机被合并——它们永远停留在最碎的碎屑情状,每一个字都被拆成三四个字节碎屑,每个碎屑各占一个 Token。
想象一下:一个缅甸语用户和一个英文用户买雷同的 API 额度,但缅甸语用户只可用英文用户五分之一的信息量。雷同的钱,五分之一的服务。

这跟电报很像。
电报编码——莫尔斯码——是这样遐想的:最常用的字母用最短的编码。E 是一个点,T 是一个划,A 是一丝一划。而不常用的字母用更长的编码——Q 是两齐整丝一划,Z 是两划两点。
但莫尔斯码是基于英翰墨母频率遐想的。当电报时候实行到全寰宇的时期,其他语言若何办?汉文若何发电报?汉字不是字母,你不成径直用点和划来编码。
解决有计议是:给每个汉字分拨一个四位数字编码——0001 到 9999。发电报的时期,先把汉字翻译成数字,再把数字翻译成莫尔斯码发出去。一个汉字等于四个数字,每个数字都要用莫尔斯码一一发送。
一个英翰墨母平均需要 2 到 3 个莫尔斯码信号。一个汉字呢?四个数字,每个数字平均需要 5 个信号——系数梗概 20 个信号。
雷同一个酷爱,汉文电报的信号量是英文的七八倍。电报是按字数或者按信号量计费的,是以汉文电报比英文电报贵得多。直到八九十年代,小学生写稿文还有个锻真金不怕火,等于写电报,看谁能用最少的字把事情阐明晰。
雷同的事情束缚在重叠。
打字机在 1870 年代发明,但却是为拉丁字母遐想的。最早的汉文打字机是什么神情?一个金属托盘上排着几千个铅字,打字员用小杆子一个一个找,速率是英文的十分之一。其时许多东说念主,包括鲁迅在内,得出结酬劳汉文是过期的翰墨,中国想要走向漂后,汉字就得拉丁化。
对这段历史有酷爱的一又友,可以望望墨磊宁的《汉文打字机》这本书,我就不张开了。我想说的是,近当代以来,每一次东说念主类发明一种新的信息编码系统——电报、打字机、诡计机、AI——都会再行制造一次语言不对等。而况这种不对等的处所简直每一次都是一样的:英文最低廉、最高效、最浅显,然后按语言与英文的「距离」递减。拉丁字母语言其次,东亚语言再次,南亚和非洲语言最末。
谁的语言首先被编码,谁等于程序;自后者永远在适配。
天然,你可能说,时候是中立的,这不是有益愤慨。BPE 不是有益愤慨汉文或者缅甸语,它只是按频率统计作念了最优压缩。
对。完全对。莫得东说念主有益愤慨。你不需要有益愤慨,你只需要采用一个「合理的」来源——比如「按频率统计」——然后让系统自动运行。不对等会我方涌现出来。
因为「频率」不是一个客不雅的天然属性。它是由谁在分娩内容、谁的语言在互联网上有最多的翰墨、谁的文化有最发达的出书和传播体系来决定的。
BPE 把这种历史性的职权不合称,通过一个看似中性的算法,编码进了 AI 系统的最底层。然后这个系统给全寰宇通盘东说念主使用。每一个东说念主,每说一句话,都在为这种不对等付费。而他们中的大多数东说念主以至不知说念 Token 是什么。

天然这个事情也在改善。
我作念了一个测试。翻开 OpenAI 的 tokenizer 用具,输入团结句汉文:「马嘉祺是时间少年团队长,蔡徐坤不是。」然后切换不同版块的 tokenizer 望望各需要些许 Token:
GPT-3.0 的 tokenizer:38 个 Token,
GPT-3.5 和 GPT-4.0 的 tokenizer:26 个 Token,
GPT-5 的 tokenizer:15 个 Token
团结句话,三代模子,Token 浮滥从 38 降到了 15,降了 60%。
这阐明 OpenAI 在每一代模子中都在给汉文更多的词表席位,让更多的汉字和常见词组被完整保留,而不是拆成碎屑。
汉文用户有十几亿东说念主。商场够大,买卖能源够强,是以 OpenAI 茂盛优化。中国我方的 AI 公司也在作念雷同的事。豆包、千问、月之暗面等等——这些国产大模子都在我方检修 tokenizer,策略很粗拙:在词内外给汉文更多的「席位」,让更多的中翰墨符组合被合并成独处的 Token,减少汉文被拆碎的概率。
但词表总容量是有限的。GPT-5 的词表梗概 20 万个 Token。你给汉文多一个席位,就得给其他语言少一个。汉文有大公司撑腰。但前边提到的那些小语种,莫得东说念主为它们作念这件事。
缅甸语有五千多万东说念主在说。藏语呢?宗卡语呢?这些语言的 tokenizer 效用,从 GPT-3 到 GPT-5,大约率莫得同等幅度的改善。因为莫得买卖能源,莫得十几亿用户的商场在那里等着。
语料配比——用些许英文、些许汉文、些许缅甸文来检修 BPE——试验上是一个隐性的决策:谁的语言更值得被高效闪现?这个决策莫得东说念主公开计议过。它埋在时候文档的某一滑参数里。但它决定了数十亿东说念主使用 AI 的资本和体验。
BPE 用频率取代了 Type。它不再由东说念主类来界说什么是一个有道理的单元,而是让统计数据我方决定。这个采用带来了语言不对等——高频的语言被完整保留,低频的语言被碎成碎屑。
但这个后果不单发生在语言和语言之间,它雷同发生在团结种语言里面。

回到马嘉祺。
我照旧不成给出确切的论断,究竟为什么大模子不领路「马嘉祺」,但可以信赖与 Token 生成联系。想象你在玩拼图游戏。常见的图案——比如「天安门」、「长城」——厂家会给你完整的大块拼图,一块就能拼出来。但淡薄的图案——比如某个小众景点——厂家莫得专门的大块,你只可用许多小碎屑免强。
「祺」这个字等于阿谁小众景点。它在检修数据里出现的频率不够高,BPE 算法莫得给它分拨一个完整的 Token,而是把它拆成了两个小碎屑。这两个碎屑单独看都没什么道理,就像拼图的边角料。
咫尺问题来了。当 AI 要生成「马嘉祺」这个名字时,它需要先找到「马」,再找到「嘉」,终末找到「祺」的那两个小碎屑,把它们按正确依次拼装起来。但 AI 在检修时很有数过这个组合——「马嘉」加上那两个特定碎屑——出现的次数太少了。
相背,「马俊杰」、「马杰伦」这些组合,每个字都是完整的大块 Token,而况这些组合在检修数据里出现过更屡次。对 AI 来说,这些组合就像是一条被走过许多遍的路,路面平整、标志知道。而「马嘉祺」就像是一条简直没东说念主走过的小径,路标迟滞、碎石随处。
当 AI 要生成谜底时,它会天然则然地采用那条更平整的路。不是因为它「不领路」马嘉祺,而是因为在它的 Token 系统里,「马嘉祺」这条路从一初始就莫得被修好。
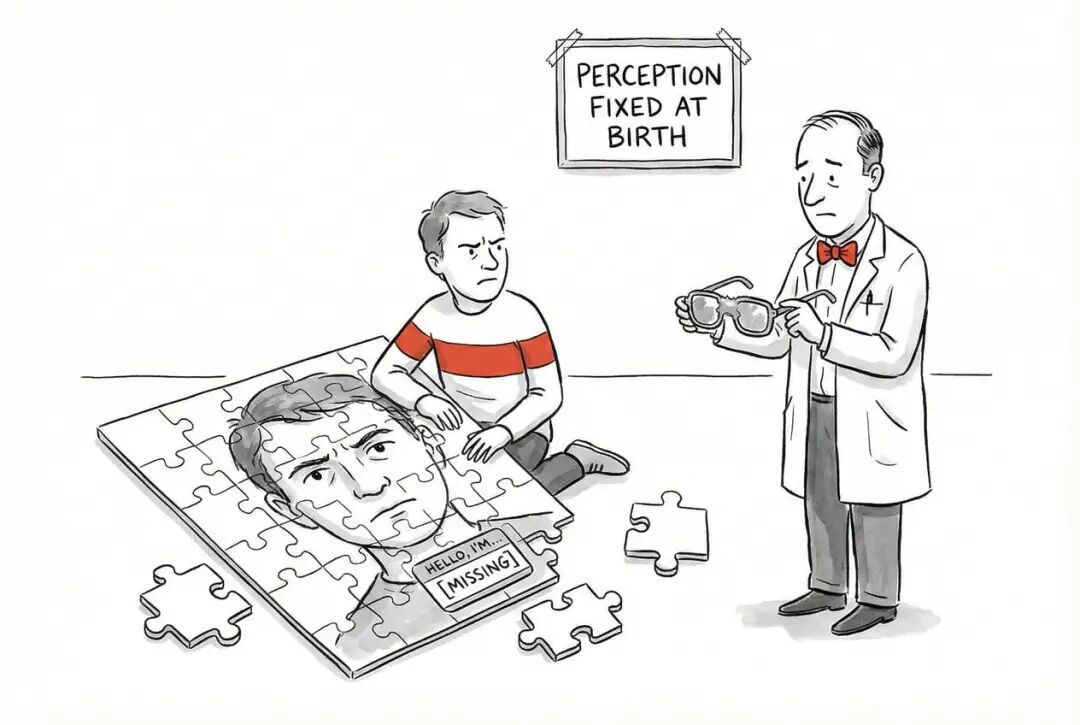
雷同的问题还有许多,在大模子领域有个专门的名词,就叫 Glitch Tokens(故障词元),酷爱是那些会让大模子运行出问题的 Token。
你可能会想:那把模子作念大一丝、作念强一丝,不就解决了?刚刚不也说,从 GPT-3 到 GPT-5,如实汉文 Token 效用在擢升。
很晦气,不成。
2026 年 1 月有一篇对于 Token 的论文《Say Anything but This: When Tokenizer Betrays Reasoning in LLMs(什么都能说,等于不成说这个:当 Tokenizer 反水了大模子的推理才调)》。
商酌者发现了一件事:tokenizer 给模子提供了一条「阻力最小的旅途」。当模子需要生成某个谜底的时期,若是词内外恰好有一个现成的 Token 能径直输出,模子就会走这条捷径,而不是实在去推理。
我举个例子让你感受一下。假定模子需要复兴「52 加 37 等于些许」。正确谜底是 89。但若是词内外恰好有一个 Token 对应 「88」,而况这个 Token 在模子的里面空间里离 「89」 很近、出现频率很高——模子可能就会滑向 「88」。不是因为它不会算,而是因为 「88」 这条路更丝滑。
商酌者作念了一件反直观的事:他们把这些捷径堵住了——强制移除那些容易变成耻辱的 Token,逼模子走推理的路。
闭幕呢?模子反而发达更好了。
这阐明什么?阐明模子自身有推理才调。问题不在「脑子」——在「眼睛」。Tokenizer 是在模子检修之前就冻结的感知器官,模子再强也改不了它。
这就好比你给一个天才画家戴上一副度数不合的眼镜,而况这副眼镜焊死在脸上了,这辈子摘不下来。他画技富贵,构图、色调、光影都对,但迢遥阿谁东说念主名字里的淡薄字,他等于看不清。
不是脑子的问题,是眼睛的问题。
论文得出论断:模子变大不成解决这个问题,Scaling 无效。因为问题在架构层面——tokenizer 在模子检修之前就固定了,模子再大、参数再多,亦然在一个被固定的感知框架里检修出来的。
眼睛的分辨率,在诞生前就定了。这等于 BPE 肃清 Type 的实在代价。

当 Type 是东说念主界说的时期——比如在编译器里——东说念主可以确保每一个被界说的类别都是完整的、精确的、莫得歧义的。`int` 等于 `int`,毫不会和 `integer` 耻辱,因为遐想者明确国法了它们的区别。
但当你把 Type 的界说权交给频率统计,你得到的「类别」就不再有这种保证了。高频的组合被识别得又快又准,低频的组合就迟滞、落空、容易耻辱。
不是均匀的不完好意思,而是有一条知道的断裂线——沿着频率分散的长尾画下去。
这意味着什么?
意味着你叫「张伟」,AI 不会写错你的名字。但你叫「马嘉祺」,它可能每次都写错。你用英文问它问题,它的复兴精确而指导。你用缅甸语问团结个问题,它的复兴碎屑化、不连贯、以至可能是错的。
这不是两种不同的 AI。是团结个 AI,用团结个 tokenizer,在频率弧线的两头展现出的两张式样。
在高频的那一端——英文、常用词、热点话题——它看起来无所不知、无所不成。这是你在应付媒体上看到的阿谁 AI,是科技公司在发布会上展示的阿谁 AI,是黄仁勋说价值万亿好意思元的阿谁 AI。
在低频的那一端——小语种、淡薄字、冷门学问——它变得蠢笨、迟滞、不可靠。但这一端的用户,恰好是那些最空泛替代信息来源的东说念主。
在 Token 的寰宇里,「罕有」和「不遑急」在统计上是团结件事。
这等于为什么法律文本用 AI 扶助的时期,罕有的术语可能会被迟滞处理。医疗会诊用 AI 扶助的时期,罕有病的名字可能会变成碎屑。训导内容用 AI 生成的时期,少数语言的学问可能会被跌跌撞撞地免强。不是有东说念主有益忽略了这些——而是这个系统从一初始就莫得才调差异「罕有」和「不遑急」。
AI 最不准确的地方,恰好是东说念主们最需要它准确的地方。

这亦然为什么我在开头说,「词元」不是一个好的翻译。
「词」字默示 Token 是一个「词」层面的单元。但你咫尺还是知说念了,Token 不是词。它可以是一个完整的词,也可以是半个字,也可以是一串毫无道理的字节碎屑。BPE 生成的 Token 不撤职任何语言学上对「词」的界说——事实上,BPE 的全部道理就在于肃清了「词」这个认识。
「元」字有「基本单元」的酷爱——元素、单元、元件。这默示 Token 是一个踏实的、天然的、有明确范畴的基本粒子,好像它是语言内在结构的一部分,以至是词的某种试验特征。但 Token 的范畴不是由语言的天然结构决定的,而是由检修数据的频率分散决定的。换一批检修数据,团结个字可能从一个 Token 变成两个 Token,或者从两个变成一个。它是一个统计产物,不是一个语言学认识。
前边说过,Token 是语言的替代物——它不是语言自身,更不是语言的某种试验,它只是一个代替语言被诡计机处理的编号。但「词元」这个译名恰恰把这层关系掩蔽了。这就好比你造了一辆莫得处所盘的自动驾驶汽车,然后给它起名叫「处所盘号」。
但非论叫它什么,Token 还是在这里了,还成了黄仁勋口中所说的「万亿好意思元商场的基础」。他说,NVIDIA 的 AI 芯片是「Token 的锻造机」。
你可能会想:既然 Token 有这样多问题——bug、不对等、幻觉——为什么它还能成为万亿好意思元商场的基础?
因为职权的基础,从来就不是完好意思的东西。

好意思元。1971 年之前,好意思元和黄金挂钩——一盎司黄金 35 好意思元,证据实在。那时期好意思元有一个「本色」在维持它:黄金。1971 年,尼克松取消了金本位。从那以后,好意思元靠什么?靠民众信赖它有价值。
2008 年金融危境,全寰宇发现——度量衡没变,但桶里是空的。那些评级为 AAA 的金融家具,下面是一层一层的次级贷款。替身看着光鲜亮丽,本色早就烂了。
但好意思元崩溃了吗?莫得。它不息是全球储备货币。为什么?因为在它崩溃之前,替代它的资本还是高到没东说念主承受得起。全寰宇的贸易公约用好意思元结算,全寰宇的央行用好意思元储备,全寰宇的大批商品用好意思元订价。你可以说好意思元有问题,但你拿什么替代它?欧元?东说念主民币?每一种替代有计议的切换资本都是天文数字。
比特币。一个算法加一群东说念主的信仰。能耗无理,价钱剧烈波动,每秒处理的交游量还不如一家县城超市的收银台。但莫得阻隔它成为一种职权载体。
以至语言自身。汉字笔画依次谁国法的?英语拼写为什么这样不国法?为什么 Wednesday 中间有一个不发音的 d?为什么 island 里有一个不发音的 s?莫得东说念主「遐想」了这些。都是历史未必的层层辘集——某个世纪的某个抄写员写错了一个字,后东说念主一误再误,失误凝固成了范例。但语言照样运转,照样承载了东说念主类全部的漂后。
Token 的故事不是一个骗局,也不是一个幻觉,它只是一个未必中诞生又在历史里起升沉伏最终领有了职权的词语。

1906 年,皮尔士在商酌逻辑图时建议了 Type-Token 差异,他只是想数明晰纸上有几个圆圈。
1994 年,Philip Gage 在《C Users Journal》上发表了一个压收缩用具,他只是想在内存有限的工控开荒上省俭几个字节。
2016 年,Rico Sennrich 把这个压缩算法用到了神经机器翻译,他只是想解决翻译中的生词问题。
2018 年,OpenAI 把 BPE 改成了 Byte-level,他们只是想让 GPT-2 能处理更多语言。
每一步都是合理的。每一步都是局部的。每一步都解决了其时的问题。
这等于职权最常见的诞生模式,不是有东说念主坐下来全心遐想了一个管辖系统——而是一连串其时看起来合理以至不足轻重的采用,在没东说念主注释的情况下,凝固成了新的纪律。
咱们都知说念,咫尺是一个历史转霎时刻,不单是是通用东说念主工智能取代东说念主类,亦然东说念主类正把什么是道理、什么是国法的界说权交给统计数据。
咱们通盘东说念主,正站在这个转机的中间现金凯发·k8国际app平台,还没来得及想明晰这意味着什么,就还是在拥抱它了。
当前网址:http://www.dazuoye.com/zixun/1288200.html
tag:现金凯发·k8国际app平台,Token,到底,是什么,咫尺,常见
- 发表评论 (191人查看,0条评论)
-
- 最新评论